
Introducing Neural Networks, Decision Trees and Support Vector Machines
Leonie Gehrmann & Dr. Sabrina Haas
In this day and age, big data has become a frequently used term to characterize data with a high velocity, volume, and variety (Chintagunta et al. 2016). For one, much of the data used today is available almost instantly. Further, developments such as the extensive usage of smartphones and social media have contributed to the ease with which personal data can be tracked, resulting in large databases for firms to draw from. Finally, existing numerical data is now extended by images, videos, and texts. Arguably, most of this data remains unexploited by both marketing practitioners and researchers alike. However, by adopting methods from fields such as machine learning and data science, valuable insights can be drawn, facilitating and refining marketing practices. For example, Kosinski et al. (2013) show that mining Facebook data provides an accurate prediction of individuals’ psychodemographic profiles, which can be used for targeting.
Interest in machine learning and artificial intelligence has surged in recent years with these buzzwords garnering widespread recognition in both business practice and research. Machine learning, or the capability of computers to learn and generate insights from data without being told specifically what to look for, belongs to the field of artificial intelligence (Balducci and Marinova 2018). By making use of the patterns found in most nonrandom data, a machine learning algorithm derives information on the properties of training data to learn a generalizable model (Segaran 2007, p.3). Thereby, it uses the aspects it considers important to consequently make predictions for previously unseen data (Segaran 2007, p.3). While machine learning methods that train using an exemplary set of inputs and corresponding outputs are cases of supervised learning, unsupervised learning methods do not have labeled examples to learn from, requiring the computer to find an unknown structure in a given data set (Balducci and Marinova 2018). This blog post will introduce the supervised task of classification, briefly explain three classification algorithms, and highlight recent marketing research addressing one of them, the support vector machine (SVM).
Classification techniques are regularly employed to make sense of both structured and unstructured data. Thereby, the lack of flexibility of rule-based approaches is solved through machine learning methods (Segaran 2007, p.118). Applications of machine learning to classification tasks allow for the recognition of complex patterns, the distinction between objects dependent on their patterns, and finally the prediction of an object’s class (Huang and Luo 2016). A classifier is given some set of data with items, their features, and class labels from which it learns with the goal of classifying previously unseen data. All classification methods aim to assign an input vector to a finite number of discrete and usually disjoint classes (Bishop 2006, p.179). In general, classification often finds its use in the preprocessing and automatic organization of data, which allows for a quick and accurate retrieval of data points in large databases (Datta et al. 2008).
Besides SVMs, common machine learning classification techniques include neural networks and decision trees. All neural networks contain a set of neurons, or nodes, that are connected by synapses Figure 1 here (Segaran 2007, p.74 & p.285). Each synapse has an associated weight that determines the degree of influence the output of one neuron has on the activation of another. Neural networks can start with random weights for the synapses and learn through training (Segaran 2007, p.287). Most commonly, the network is fed an exemplary input and corresponding output and adjusts the weights of each synapse proportionally to their contribution to the nodes in the output layer, a process called backpropagation (Segaran 2007, p.287). The training occurs slowly, allowing the classification of an item to improve with the number of times it is seen and preventing an overcompensation in response to noisy data (Segaran 2007, p.287). Overall, neural networks capture the interdependence between features by allowing the probability of one feature to vary with the presence of others (Segaran 2007, p.140). Additionally, they are applicable to cases with a continuous stream of training data due to their incremental training (Segaran 2007, p.288). However, in cases with an abundance of nodes and synapses in hidden layers, this algorithm resembles a black box, making it impossible for researchers to understand the rationale behind classifications (Segaran 2007, p.288).

The concept of decision trees is likely one of the more generally known classification methods, since it proves a straightforward graphical representation of a decision. As a simple machine learning method, items are classified by beginning at the top node and following a sequence of yes or no decisions until the final node and predicted class is reached (Crone et al. 2006). A common training method is to build the tree from the top, with the choice of each next division criteria maximizing the information gain until further division of the data on each branch does not result in any additional information gain (Segaran 2007, p.283). The intuitive interpretation of decision trees is one of the reasons for their widespread application in business analysis (Segaran 2007, p.155). The ability to understand which variables contribute to the classification and which do not provides practitioners with valuable information for topics such as cost saving and targeting (Segaran 2007, p.164). Furthermore, decision trees are valuable due to their capability of handling both categorical and numerical input data (Segaran 2007, p.164). Nevertheless, since decision points can only divide numerical values at some break point, they are less adequate for cases with complex relationships between numerical inputs or with many numerical inputs and outputs (Segaran 2007, p.165).
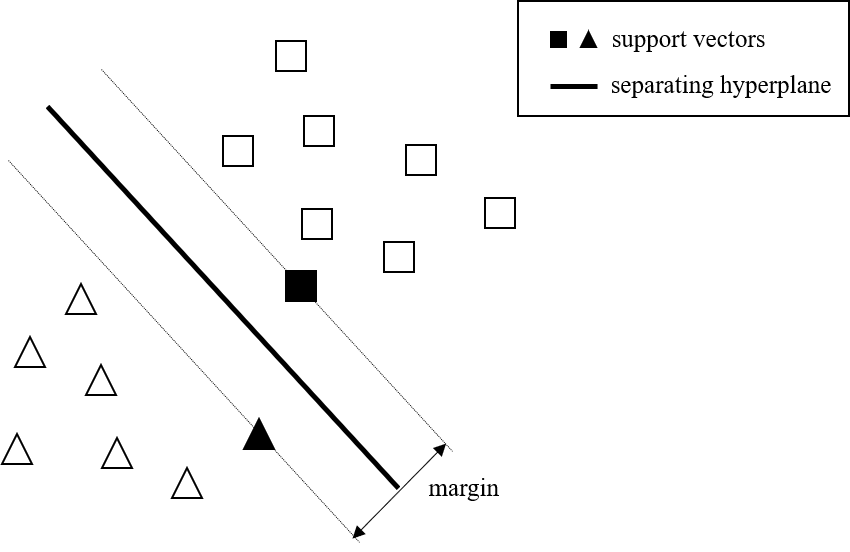
The idea behind the SVM is to classify items into one of two classes by determining the hyperplane that separates the data with the largest margin, which is why the classifier is also referred to as the maximum margin classifier Figure 2 here (Cui and Curry 2005). The margin is defined as the sum of the shortest distance between the hyperplane and the closest point in the first class and the shortest distance between the hyperplane and the closest point in the other class (Burges 1998). These closest points in each class lie on two hyperplanes parallel to the separating hyperplane and are referred to as the support vectors (Burges 1998). Notice that these are the only points required to describe the data set for the solution and omitting them would change the solution.
Even so, this method has many limitations. Since the number of required support vectors generally increases linearly with the size of the training data set, SVMs end up requiring a complex computation unless a post-processing is performed (Tipping 2001). Moreover, a SVM returns a binary classification as output, opposed to the posterior probabilities necessary to account for uncertainty in the prediction (Tipping 2001). Finally, the transformation into high-dimensional space complicates the interpretation of the classification, making SVMs a black box technique like neural networks (Segaran 2007, p.292). Nevertheless, once the parameters are appropriate and training has concluded, SVMs are quick and powerful classifiers (Segaran 2007, p.292). Two valuable extensions to the basic idea allow for training data that is not separable or classification in the non-linear case. The simultaneous minimization of error on the training data set and maximization of the margin effectively lets SVMs avoid overfitting, resulting in a sparse model that makes good generalizations (Tipping 2001). Furthermore, their ability to deal with high-dimensional data sets makes them valuable for data-intensive problems or problems with complex data, such as facial expression classification (Segaran 2007, p.216, Lu et al. 2016).
Due to its potential, the focus of this post is to highlight applications of SVMs in academic marketing research. Generally, the existing work can be divided into three broad categories. Some researchers aim to comprehensibly develop the theory of SVM for marketing purposes, others evaluate the performance of SVM in comparison to other classifiers, and finally some research incorporates SVMs into a larger methodology or approach.
For example, Cui and Curry (2005) evaluate the use of SVMs in prediction models for marketing. Similarly, Evgeniou et al. (2005) propose the use of SVMs in conjoint analysis to accommodate large data sets and interactions between product features. More recently, Martens and Provost (2014) set out to aid users in understanding data-driven document classification and extend an existing framework to show that explanations for intelligent systems reduce the gap between a classification decision system and its user’s mental model.
Following the introduction of SVM into marketing literature, researchers have also evaluated its performance compared to existing methods in the estimation of the relative purchase likelihood (Martens et al. 2016), the development of a task recommendation system (Mo et al. 2018), or the automatic classification of unstructured text (Hartmann et al. 2019). Other researchers use SVMs to examine the robustness of their analysis (e.g. Geva et al. 2017, Fang et al. 2013).
However, the majority of marketing research that addresses SVMs applies the ML method as a part of their approach. A canvassing of the body of literature suggests that until now, SVMs are often used to classify text (e.g. Abbasi et al. 2018, Pant and Srinivasan 2013, Homburg et al. 2015). Many recent studies document that SVM classifiers have also found their way into the Word-of-Mouth (WOM) literature (e.g. Luo et al. 2017, Hennig-Thurau et al. 2015, Marchand et al. 2017). Similarly, research addressing user-generated content (UGC) has drawn on the ML approach for classification (e.g. Archak et al. 2011, Tirunillai and Tellis 2012, Ghose et al. 2012, Lu et al. 2013). Finally, a few marketing researchers have also combined SVMs with sophisticated methods such as neural profiling (Chan et al. 2018), video-based automated recommender systems (Lu et al. 2016), or adaptive decompositional preference elicitation (Huang and Luo 2016).
Discussion
Summarizing, machine learning is a subfield of arficial intelligence that involves computers’ capability of learning and generating insights from data without an explicit cue what to look for. Supervised machine learning methods train using a labeled data set and require human guidance, whereas unsupervised ML methods do not, finding previously unknown structures in a data set on their own. Classification is a systematic two-stage approach that assigns items to a finite number of classes. Supervised machine learning methods such as neural networks, decision trees, and SVMs are applied to facilitate classification tasks and increase flexibility. When using neural networks, the class of an input is determined according to the weight of the synapses and the activations between the nodes. Decision trees are easily interpreted, which is why most people have likely been confronted by one at some point. This classifier uses a sequence of binary decisions to arrive at the predicted class of an item. Finally, SVMs are valuable for their capability of handling high-dimensional data. The idea is to find the hyperplane that maximizes the margin between two classes.
The value of SVMs lies in their ability to classify high-dimensional data and this capability is promising for marketing purposes. More specifically, highly unstructured data such as videos or images are nonnumeric, multifaceted and characterized by concurrent representation (Balducci and Marinova 2018). For example, Matz et al. (2017) use previous findings suggesting that Facebook data can provide accurate predictions of psychodemographic profiles (Kosinski et al. 2013) to show the effectiveness of psychological targeting through persuasive communication. The volume, velocity, and variety of big data seems an ideal target for a SVM to tackle and generate valuable insights from. Imagine using social media chatter to pick up on desirable features for products or analyzing posted pictures to predict trends. In general, the possibilities seem endless, especially when accounting for the ability of computers to find unspecified patterns in the data.
However, as mentioned in the beginning, the potential of big data for marketing practitioners and researchers alike remains widely unexploited. For one, most machine learning classification methods do not offer a straightforward interpretation. In both business practice and research, not being able to explain how exactly you arrive at your findings can prevent acceptance. Moreover, the correct use of a SVM also requires sufficient skill and understanding. Parameters have to be chosen, code has to be written, and output has to be interpreted correctly, suggesting interdisciplinary teams might be necessary to enhance the insight gained through machine learning methods. But, the promising potential of these methods makes us curious to see what the future holds.